Performing effective population health research requires rich and diverse data that are linkable and have ongoing support. The ☞ Stanford Center for Population Health Sciences (PHS) is committed to enabling this mission and offers access to a growing portfolio of population-level data to Stanford affiliates (i.e., faculty, student, and staff) and external collaborators. In order to achieve this aim, we have devised a user-friendly portal to get you onboard with our data and streamlined many of the mandated requirements.
This page gives you the introduction to the "Data-Use Workflow" for new users to get familiarized with the processes and our data-service infrastructure (☞ learn more).
Overview
The workflow begins with a research question or a study proposal that you have prepared beforehand. Once you have formulated the question well enough to know the data you need, working with them requires 3 steps:
- Getting the access permission by fulfilling the data access requirements
- Creating a data cut by selecting your variables
- Analyzing your selected data using tools you are already familiar with
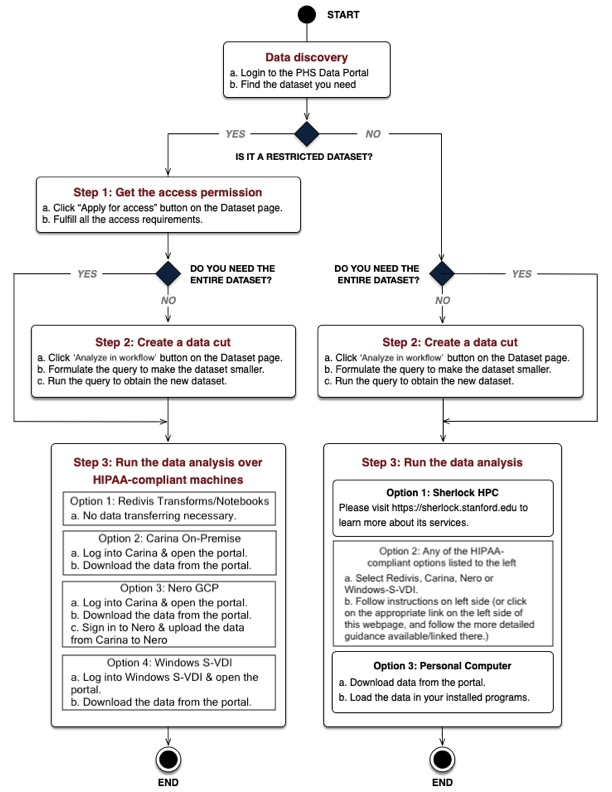
For example: Emily wants to work with the MarketScan Commercial dataset for her study. Because the dataset is a restricted dataset, she needs to get access permission by fulfilling all the access requirements (e.g., Study approval, Data Use Agreement (DUA), data security training, and so on) (Step 1, based on the flowchart above). After she receives data access approval from a PHS administrator, she realizes that she only needs some of the records and variables for her study (for example, patients between 35 - 60 with certain ICD-10 codes). In order to manage the data load, she then creates a cut of the original dataset by filtering only the records and variables that she will need for her analysis (Step 2). Finally, she wants to aggregate the total cost for each patient and she does that by utilizing the tools available in the platform (Step 3).
To further break down the process:
- Create a PHS Data Portal account
- Find a dataset of interest and apply for access to it
- Wait for approval (please allow 5-10 days for your submissions to be reviewed)
- Access the data through a Redivis Workflow
- Make a study cohort/data cut
- Transfer the data cut to an approved computational environment (the Redivis Transforms and/or Notebooks, Carina On-Premises, Nero GCP, or Windows S-VDI)
- Perform additional data cleaning and analyses
- Create final output tables (your final results)
- Check that the output tables meet security requirements (explained in the PHS Data Security Training) and download them if they do meet the requirements
- Write your abstract or manuscript
- Submit it to PHS for security and citation review (email it to support@stanfordphs.freshdesk.com, with all tables/figures you want to publish--please allow 5-10 days for your submissions to be reviewed)
- After you receive approval, submit it to the journal(s)/conference(s) of your choosing
We have integrated different software components, which were either built in house or obtained from a vendor, to facilitate availability, reliability and security in our data-service infrastructure. Our data catalog portfolio includes data sets from trusted sources that we have either purchased or curated from them to further high-quality research.
In the next three pages, we are going to describe in details each step and walk you through all the actions needed to set up your first data-driven project with us.
The PHS Data Model
PHS has created an innovative data ecosystem that enables scholars from diverse disciplines to easily and securely access, link, and analyze an extensive portfolio of population-level datasets, including high-risk health data. Our secure, cloud-based data infrastructure allows us to moderate access to datasets, and provides researchers with robust data discovery, analysis, and visualization tools, enabling them to explore questions and data sources that would previously have been out-of-reach.
| Traditional Data Access Model | PHS Model |
|---|---|
| Data is difficult to find, and applying for access is slow and complex | High-quality datasets are easily discoverable through a centralized system, and pathways to data access are clear and streamlined |
| Data is only available to a select few via lab-specific servers or individual computers, making it difficult to collaborate without risking data security | Data is available to the entire university, as well as external collaborators, but controlled in a secure and monitored environment |
| Each research group independently completes labor-intensive data cleaning and curation | Pre-cleaned and curated datasets are available via on-premises and cloud systems, minimizing duplication of efforts and ensuring that the data are appropriate for a wide range of research questions |
| Large datasets can be difficult to wrangle, cut and analyze | New visualization and analytic tools limit the amount of wrangling required, and simplify cohort creation and data analysis |
| Data is not harmonized, so replication of research is difficult and time-consuming | Data is transformed into a common model, so replicating research in multiple datasets and incorporating new datasets is simpler and more reliable |
| Those with access to the best data are the most likely to receive recognition for their work | Those with the best ideas and highest-quality projects are the most likely to receive recognition for their work |
About Stanford Affiliation
If you are not formally affiliated with Stanford (i.e., not a faculty, not a paid staff member, not a student, not an HR-Recognized Visiting Scholar), please be aware of our policy below.
Stanford Affiliation - Full: For many of our datasets, we have a contractual obligation to ensure that only Stanford faculty, staff, students and those with some other formal Stanford affiliation are able to access data. For example, we are unable to share our commercial claims datasets with outside entities (including academic collaborators) without completing data rider agreements with the data proprietors. If you have any questions about this, please ☞ contact PHS at support@stanfordphs.freshdesk.com .
Stanford Affiliation - SU External Collaborator: For some of our datasets, we are able to share with outside collaborators if the collaborator has a Stanford PI and a fully sponsored SUNet stem email. There may be additional contractual requirements so please be sure to check with PHS any time you are considering extending data access to non-Stanford personnel. We are always looking for ways to collaborate but must balance this with the need to keep the data safe and protect Stanford.